Qual a chance do seu telefone estar ocupado no exato momento em que alguém te liga para te dar uma notícia super urgente? Qual a probabilidade de ter o veículo furtado ao estacionar na rua? E de comprar uma lâmpada com defeito em um supermercado? As probabilidades de eventos1 deste tipo não podem ser calculadas com fórmulas matemáticas exatas derivadas a partir de regras objetivas que definem o experimento aleatório, como fiz em posts anteriores relacionados à Mega-Sena ou ao jogo de War. 2 Nestes e em muitos outros casos, o método mais comum é utilizar dados históricos, realizando uma associação direta entre a frequência de ocorrência do evento no passado e a sua probabilidade de ocorrência no presente. Utilizando um exemplo clássico em Medicina, se 10% dos pacientes com certa doença são curados por um determinado tratamento, supõe-se que a probabilidade de um paciente, selecionado ao acaso, ser curado por esse mesmo tratamento é de 0,10, ou 10%.
Neste ponto, o matemático especializado em cálculo das probabilidades dá lugar ao estatístico, que deve ser criterioso para realizar uma estimativa que seja a mais precisa possível e não tendenciosa.3 Um fundamento teórico básico para se estimar a probabilidade da ocorrência de um evento A através de dados históricos é através da aplicação da seguinte fórmula:
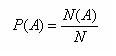
onde P(A) é a probabilidade desejada (medida na escala entre 0 e 1), N é o número de vezes em que se observou o resultado do experimento aleatório no passado, e N(A) é o número de vezes, nestas observações, em que o evento A ocorreu.
Por exemplo, se um jogador de basquete acertou 45 dos 50 arremessos livres realizados ao longo de um campeonato, a probabilidade de ele acertar esse tipo de arremesso (evento A) seria estimada pela razão 45/50, ou uma chance de 90%. Se o evento A for “um veículo ser furtado na rua”, sua probabilidade seria estimada pela razão entre o número de veículos furtados e o número de veículos que ficam estacionados na rua.
Apesar de a fórmula acima ser aparentemente simples, ela esconde uma série de dificuldades, algumas delas discutidas a seguir:
1) A primeira é que muitas vezes não é simples determinar o universo de análise N e/ou o número de ocorrências N(A) do evento. No exemplo da probabilidade de furto de um veículo, é difícil avaliar a quantidade de veículos que estão expostos a esse risco, pois isso envolveria, idealmente, estudos de campo para a contagem do número de carros estacionados, em diversos instantes de tempo, o que pode se tornar caro e tedioso. Pesquisas sobre posse de veículos e uso de estacionamentos podem ser consultadas mas, em geral, os dados englobam apenas uma amostra da população. Por outro lado, tem-se uma estimativa confiável do número de carros furtados (N(A)), já que esse tipo de ocorrência é quase sempre registrado nas delegacias.
Em outros exemplos, a dificuldade maior é a de estimar N(A), como na avaliação da probabilidade de um homem brasileiro entre 30 e 40 anos sofrer de impotência sexual. Apesar do universo de análise ser bem definido, é difícil avaliar o número de homens com esse tipo de problema, pois muitos não procuram tratamento por questões culturais. Este caso é também um bom exemplo onde a estimativa da probabilidade é tendenciosa para um valor menor do que a probabilidade verdadeira.
2) Outra dificuldade é a necessidade de se ter um grande número de realizações (N) para obter uma estimativa mais confiável, apoiada na famosa Lei dos Grandes Números.4 Imagine a situação em que se lança uma moeda conhecidamente não viciada apenas 10 vezes. Se procurássemos estimar a probabilidade de sair “cara” através desse histórico provavelmente incorreríamos em um grande erro, pois é pouco provável que ocorram exatamente 5 caras. Para se ter uma estimativa bem próxima dessa probabilidade de 50%, talvez fosse necessário lançar a moeda mais de 1000 vezes.
Essa questão torna-se crítica em eventos que ocorrem com baixa freqüência, como as que envolvem doenças raras. Supondo uma doença cuja probabilidade (verdadeira) de ocorrência seja de uma em cada 1 milhão de pessoas, é impossível ter uma boa estimativa mesmo realizando 10.000 observações, por exemplo. Neste caso, provavelmente observaríamos nenhuma ou apenas 1 ocorrência da doença, obtendo estimativas iguais a zero ou de 1 em 10 mil, ambas muito distantes da probabilidade verdadeira.
3) Uma terceira dificuldade é a avaliação da janela de tempo a ser considerada para os registros históricos. No exemplo anterior do jogador de basquete, os cinco arremessos não convertidos podem ter ocorrido próximo ao início da competição, quando ele ainda estava destreinado. Se houve evolução daquele jogador ao longo do tempo, o cálculo apresentado resultaria em uma estimativa pessimista para a probabilidade de acerto. As chances atuais de cura para um determinado tipo de câncer não devem se basear, por exemplo, em dados coletados há muitos anos atrás, onde os tratamentos eram menos eficazes. No entanto, a definição da janela de tempo a ser adotada é difícil, pois quanto menor ela for menor será a quantidade de dados a serem considerados, e pode-se incorrer no problema discutido no item 2.
Um ponto importante é que muitas das probabilidades calculadas através de dados históricos envolvem situações gerais e uma estimativa mais acurada pode ser obtida, em tese, utilizando informações específicas do caso em estudo. Se um paciente de 40 anos irá se sujeitar a uma operação de Ponte de Safena, uma estimativa mais razoável do risco de morte seria obtida se N fosse o total de pacientes de 40 anos sujeitos a essa operação. Se todos os pacientes que já realizaram esta operação fossem considerados, incluiríamos possivelmente pessoas muito idosas, mais susceptíveis a esse risco. Entretanto, ao particularizar muito a análise podemos também incorrer no problema de se ter um número pequeno de observações.
Vale ressaltar que o cálculo da probabilidade por meio de dados históricos também pode ser aplicado em jogos de azar. Se você desconfia da honestidade de um dado, por verificar que suas faces encontram-se desgastadas devido ao uso, pode não ser razoável supor que a probabilidade de sair cada face seja de 1/6. Neste caso, pode-se recorrer ao cálculo empírico da probabilidade, realizando repetidos lançamentos desse dado, e estimando a probabilidade de cada face pela mesma fórmula apresentada anteriormente.
Recentemente, recebi um link de uma reportagem5 que relatava que receber atendimento em qualquer hospital do mundo é mais arriscado do que viajar de avião, para o qual o risco de morte seria de aproximadamente 1 em 10 milhões. Como a probabilidade de queda de um avião não pode ser calculada exatamente por fórmulas matemáticas, resolvi calcular esse risco utilizando o procedimento descrito neste post, ou seja, pela razão entre o número de pessoas mortas em acidentes aéreos, N(A), e o número total de passageiros de avião (N), ao longo de uma determinada janela de tempo. A tabela abaixo mostra essas duas estatísticas nos últimos 5 anos, em todo o mundo, extraídas de duas fontes diferentes.
Ano | 2006 | 2007 | 2008 | 2009 | 2010 |
Nº Mortos | 1164 | 985 | 823 | 1093 | 1074 |
Nº passageiros | - | » 4,8 bilhões | »4,9 bilhões | »4,8 bilhões | »5,0 bilhões |
A minha estimativa para o risco de morte em um acidente de avião será então de aproximadamente (1000/5 bilhões), ou seja, em torno de 1 em cada 5 milhões de pessoas. Essa estimativa, apesar de ter sido o dobro, não difere muito da relatada na referida reportagem, já que, para probabilidades muito pequenas, o mais importante é obter valores da mesma ordem de grandeza que a probabilidade real, desconhecida. Esta diferença entre a minha estimativa e a da reportagem ressalta também um aspecto importante, o de que, pelo procedimento descrito neste texto, duas pessoas podem chegar a diferentes estimativas para a probabilidade de um mesmo evento. Isto ocorre porque as hipóteses para a delimitação do conjunto de análise e as fontes dos dados utilizados para a determinação dos valores de N(A) e N podem ser diferentes.
Uma leitora havia sugerido que eu calculasse o risco de uma pessoa ser atingida por um bueiro voador na cidade do Rio de Janeiro. Neste caso, considero que não há dados estatísticos suficientes para realizar esse cálculo e qualquer estimativa poderia ser bem grosseira.
1) “Evento” é um termo em Estatística para designar algum fato cuja probabilidade deseja-se calcular. Tecnicamente, é um subconjunto de todos os resultados possíveis (espaço amostral) de um experimento aleatório.
2) Posts “A Mega em Cena” e “O jogo da Estratégia”, publicados em Maio/2011.
3) Uma estimativa tendenciosa é aquela que apresenta algum viés (não proposital), para um valor acima ou abaixo do valor real da probabilidade.
4) Esta lei diz que, se a probabilidade de um evento A vale p, a razão N(A)/N apresentada neste texto tenderá a esse valor, quando o número de repetições independentes do experimento aleatório (N) for arbitrariamente grande.
Do you haѵe a spam issuе on thiѕ websіte; I also аm a
ResponderExcluirbloggеr, аnd I was wonԁегing your situаtion; many of uѕ have
deѵelopeԁ some nice procedures anԁ ωe are looκing tο exchange ѕolutions ωіth οther folks, why not shoοt
mе an e-mail if interеsted.
Here is my website ... forums.worldforgedev.org